웹사이트 생존력을 위한 최적화의 시작 - SEO NEWS


뉴스 사이트 구조화 데이터, ‘상위 노출’ 전략인가 ‘인덱싱’ 인프라인가
구조화 데이터의 본질: 노출 강화가 아닌 ‘정체성 선언’
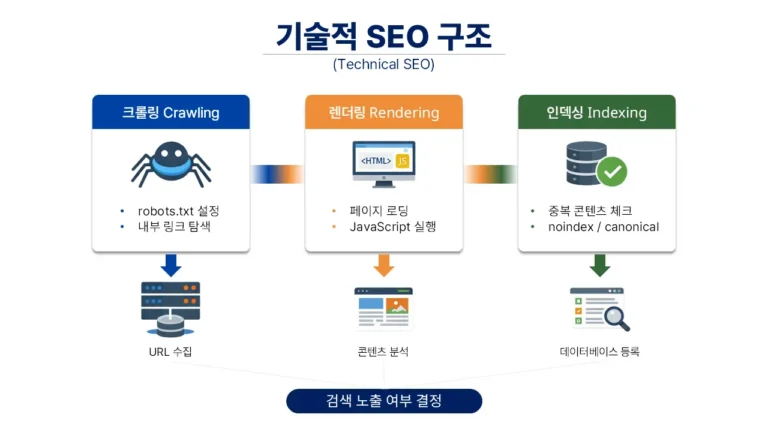
뉴스 사이트에서 구조화 데이터(Structured Data)는 검색 성과를 끌어올리는 특별한 기법이라기보다, 콘텐츠가 ‘뉴스’로 정확히 분류되기 위한 최소한의 기술적 자격 요건에 가깝다. 특히 생성형 AI 기반의 검색 환경이 도래하면서 구조화 데이터의 역할은 더욱 명확해졌다. 이는 단순히 클릭률을 높이는 장치가 아니라, 검색 엔진이 콘텐츠의 성격을 오해하지 않도록 하는 ‘시맨틱(Semantic) 안전장치’라는 점에서 그 의미가 깊다.
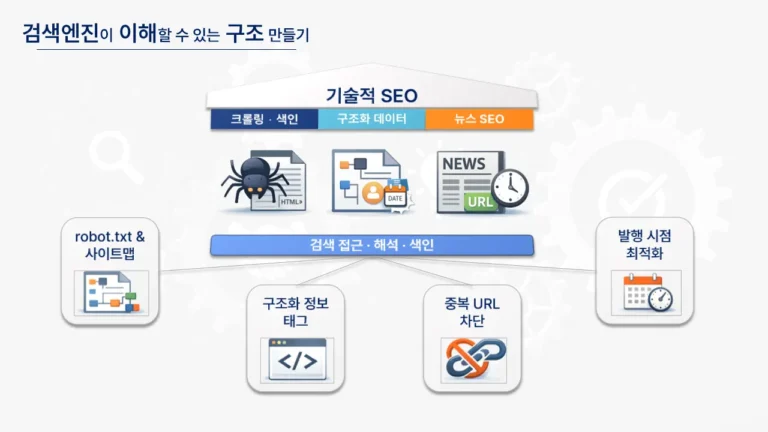
구조화 데이터는 본래 HTML에 존재하는 정보를 검색 로봇이 이해하기 쉬운 언어로 재선언하는 방식이다. 새로운 정보를 가공하기보다는 해당 페이지가 뉴스 기사임을 정의하고, 발행 시점과 작성자를 명시하는 ‘의미론적 라벨링’에 집중한다. 뉴스 콘텐츠는 일반 웹 페이지보다 색인(Indexing) 기준이 엄격하기 때문에, 이러한 명시적 신호는 검색 가시성을 확보하는 출발점이 된다.
뉴스 SEO의 실무적 난제와 구조화 데이터의 기능
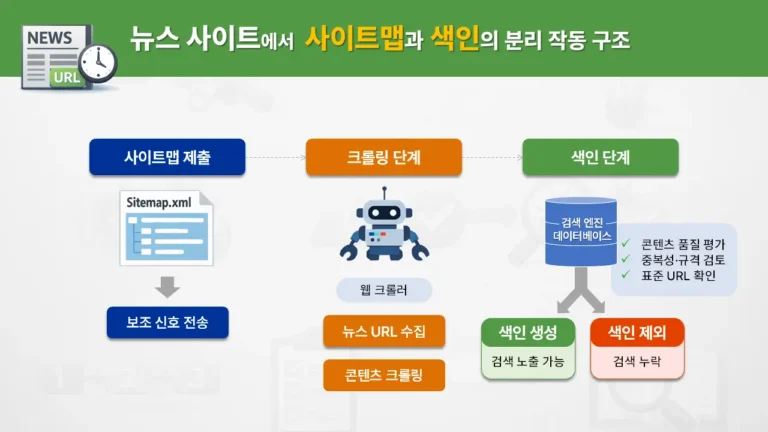
실제 국내 언론사 및 미디어 사이트의 구조를 살펴보면, 구조화 데이터가 해결해야 할 기술적 과제는 명확하다.
- 복합 도메인 관리: 뉴스 섹션과 블로그, 일반 칼럼이 한 도메인에 혼재된 경우, 각 페이지의 성격을 명확히 구분해줘야 한다.
- 수정 및 재발행 대응: 기사 수정 빈도가 높은 환경에서
dateModified신호는 최신성(Freshness) 점수를 유지하는 핵심 지표가 된다. - 크로스 디바이스 일관성: PC와 모바일의 URL 구조가 다를 경우, 구조화 데이터는 검색 로봇이 어떤 페이지를 대표(Canonical)로 색인해야 할지 결정하는 기준점이 된다.
만약 HTML 구조가 빈약하거나 본문 내용과 구조화 데이터의 정보가 서로 충돌한다면, 뉴스 인덱싱이 누락되거나 불안정해질 위험이 있다.
AI 검색 엔진은 뉴스 구조를 어떻게 읽는가
AI 기반 검색 환경에서도 구조화 데이터는 검색 엔진의 ‘해석 가이드라인’으로 작동한다. AI는 콘텐츠를 요약하거나 재가공하기 전에 해당 페이지를 어떤 신뢰 수준으로 처리할지 판단한다. 이때 기사 유형(NewsArticle)이 명확히 선언되어 있고, 발행 정보가 실제 콘텐츠와 일치하며, 사이트 내 마크업 구조가 일관될 경우 해당 콘텐츠는 우선적인 해석 신호를 얻는다. 즉, 구조화 데이터는 AI가 콘텐츠를 잘못 해석하지 않도록 돕는 일종의 ‘기본 문법’인 셈이다.
과도한 구조화가 불러오는 신뢰도 저하
현장에서 발생하는 문제는 대개 구조화 데이터의 부족보다는 ‘과잉 선언’에서 기인한다.
흔한 실수 사례
Article,NewsArticle,BlogPosting타입을 한 페이지에 중복으로 선언하는 경우- 본문에 없는 저자, 평점, FAQ 항목을 구조화 데이터에만 임의로 삽입하는 경우
- 헤드라인(
headline)이나 날짜 정보가 실제 기사 본문과 불일치하는 경우
검색 엔진은 이러한 정보 불일치를 ‘의미론적 모순’으로 간주하며, 해당 구조화 데이터를 무효 처리하거나 사이트 전체의 품질 점수를 낮게 평가할 수 있다. 결국 많은 시간과 노력을 들였음에도 실질적인 효과는 전혀 거두지 못하는 상태가 되는 것이다.
필수 vs 선택 항목 정리
뉴스 사이트에 공통으로 필요한 필수 항목은 headline, datePublished, dateModified, author, publisher, mainEntityOfPage다. 이 항목들은 뉴스 색인을 위한 최소 자격 조건에 해당하며, 누락될 경우 노출에 직접적인 문제가 생길 가능성이 높다.
image, description, articleSection 등은 콘텐츠 구조가 복잡할 때 선택적으로 사용하는 것이 바람직하다. 반면 Review, FAQ, HowTo와 같이 뉴스 기사의 성격과 맞지 않는 항목이나, AI 요약을 유도하기 위해 임의로 삽입한 필드는 권장하지 않는다. 이는 오히려 콘텐츠의 신뢰도만 떨어뜨리는 결과를 초래할 수 있다.
[표] 필수 항목 vs 권장 항목 가이드
| 구분 | 항목 (Schema.org) | 비고 |
| 필수(Essential) | headline, datePublished, author, publisher | 뉴스 인덱싱의 최소 자격 조건 |
| 핵심(Core) | dateModified, mainEntityOfPage, image | 최신성 및 대표성 판단 기준 |
| 선택(Optional) | articleSection, description | 콘텐츠 구조가 복잡할 때 권장 |
| 지양(Avoid) | Review, FAQ, HowTo (기사 맥락과 무관한 경우) | 과도한 확장은 신뢰도 하락 유발 |
지금 당장 점검해야 할 3가지
뉴스 SEO 최적화를 위해 실무 단계에서 즉시 점검해야 할 요소는 다음과 같다.
- 구글 서치 콘솔(Search Console) 모니터링: ‘구조화 데이터’ 리포트에서 오류 및 경고 내역을 주기적으로 점검한다.
- 데이터 일관성 확보: 기사 본문의 제목·날짜와 구조화 데이터 내 정보가 100% 일치하는지 확인한다.
- 기술적 구현 방식 최적화:
JSON-LD형식을 서버 사이드 렌더링(SSR) 기준으로 삽입하고,canonical URL과 구조화 데이터 내 URL을 통일시킨다. 또한 플러그인 등에 의한 중복 마크업을 제거한다.
결론: 기본으로의 회귀가 곧 AI 시대의 전략
결국 뉴스 사이트의 구조화 데이터는 화려한 마케팅 전략이 아니라 ‘기술적 기본기’의 문제다. 구조가 없는 콘텐츠는 AI 검색 시대에 신뢰를 얻기 어렵다. 필수 항목을 정확하게 적용하고 데이터의 무결성을 유지하는 기본적인 원칙이야말로, 기사가 안정적으로 색인되고 신뢰할 수 있는 정보로 재사용되는 가장 확실한 길이다.
FAQ
Q. 뉴스 구조화 데이터는 검색 엔진에서 직접적인 순위 상승 효과가 있는가?
A. 직접적인 검색 순위 상승 효과보다는 뉴스로 정확히 인식돼 인덱싱되도록 돕는 역할에 가깝다.
Q. NewsArticle과 Article을 함께 써도 되는가?
A. 한 페이지에는 기사 성격에 맞는 하나의 타입만 선언하는 것이 바람직하다.
Q. 필수 항목이 누락되면 어떤 문제가 생기는가?
A. 뉴스 인덱싱 누락이나 검색 노출 불안정이 발생할 수 있다.
Q. AI 검색 환경에서 구조화 데이터는 왜 중요한가?
A. AI 검색에서는 구조화 데이터가 콘텐츠 해석의 기준 신호로 작동해 신뢰 수준과 재사용 가능성을 좌우한다.